

Have you ever wondered why today’s programming community doesn’t follow the practice of ASCII for character encoding systems? Because it has a limit of 128 characters and covers only English. If you are working with multilingual systems, it won’t work. That’s why the community invented Unicode encoding systems.
Unicode character systems are the gold standard in the field of computer science.
As of this time, Unicode 15.1 has added 627 characters, bringing the total to 149,813 characters. In contrast, ASCII has only 128 characters and lacks platform independence.
Here are six ways:
Method 1: Using the chr() method
The impeccable way to print all Unicode characters is to use the chr() method to iterate through numbers from 0 to 0x110000 (1,114,112 in decimal), which is the range of Unicode code points.
for code in range(0x110000):
try:
print(chr(code), end='')
except UnicodeEncodeError:
pass
Output

The above screenshot is somewhat unimpressive, but you get the idea that we can effortlessly print all the Unicode characters in the console.
The chr() method accepts each number, iterating from the for loop, and converts that number into a unicode point. Based on your console’s capability and font settings, you can see various types of symbols, but that is the least of our concerns.
Drawing on my experience, this is the best approach to handling Unicode characters.
Method 2: Using list comprehension with join
You might wonder why we use list comprehension when we are dealing with characters. Well, that’s where the join() method comes into play.
List comprehension creates a new list of unicode point characters based on the existing one, and the join() method joins all the unicode characters in the list into a single string.
print(''.join([chr(i) for i in range(0x110000) if ord(chr(i)) < 0x10000]))
This code is just a one-liner, but if you are not familiar with list comprehension, you might have difficulty wrapping your head around it.
This code returns the same output as above, with one difference being that it may not handle all characters correctly.
However, this approach is more memory-efficient because it does not require a for loop, which creates iteration; iteration always incurs a memory and performance cost.
If you are looking for a cost-effective method, list comprehension is your go-to; it is the only way.
Method 3: Using the “unicodedata” module
Up until this point, we had been exploring ways that do not require the use of any specific module. However, we can use the built-in module called “unicodedata”, which is precisely designed to work with unicode points.
Just import the module at the head of the Python file, and you will be ready to proceed.
import unicodedata
for cp in range(0x110000):
char = chr(cp)
try:
name = unicodedata.name(char)
print(f"U+{cp:04X}: {char} - {name}")
except ValueError:
pass
Output
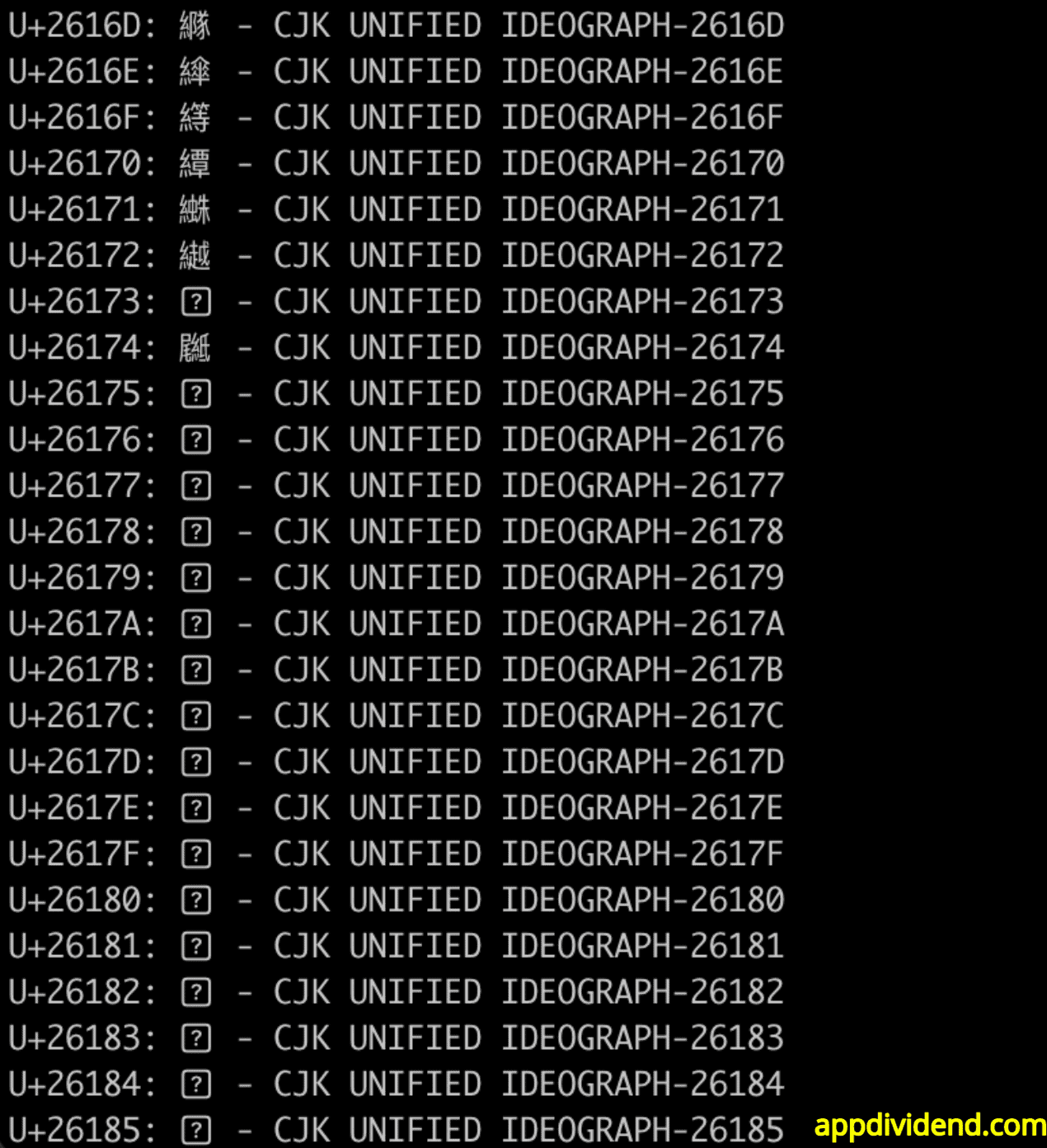
Have you noticed anything different from the previous outputs? Yes, you are correct. Here, you can see in the above output screenshot that we are printing more information about each character, including its Unicode name.
This is helpful metadata that you can use for linguistic or technical analysis, or for a variety of other purposes.
Method 4: Printing characters by category
What if I told you that you could print unicode characters by category? Yes, you heard it right.
We will create a custom function that accepts a category and utilizes the unicodedata module.category() function to match that category with the input category and print only the unicode points that belong to that category.
Here is the demonstration of what I am describing in the form of a program:
import unicodedata
def print_unicode_char_based_on_category(category):
chars = []
for cp in range(0x110000):
char = chr(cp)
if unicodedata.category(char) == category:
chars.append(char)
print(f"Characters in category {category}: {''.join(chars)}")
# Example usage:
print_unicode_char_based_on_category('Ll') # Lowercase letters
Output

As illustrated in the image above, we are only printing lowercase characters.
If you are working with linguistic analysis and dealing with a specific set of characters, this approach is profoundly helpful.
Method 5: Grouping characters by block
If you want to print specific characters grouped by block, you can also do it.
If your analysis is more focused on, for example, the “Basic Latin” or “CJK Unified Ideographs” groups, then you can use this approach because you can target this group and retrieve the characters that belong to it.
Here’s a program that displays it accurately:
def print_unicode_by_block(start, end):
block = []
for cp in range(start, end + 1):
char = chr(cp)
if char.isprintable():
block.append(char)
print(f"Characters from U+{start:04X} to U+{end:04X}: {''.join(block)}")
# Example usage:
print_unicode_by_block(0x0000, 0x007F) # Basic Latin
print_unicode_by_block(0x0080, 0x00FF) # Latin-1 Supplement
Output
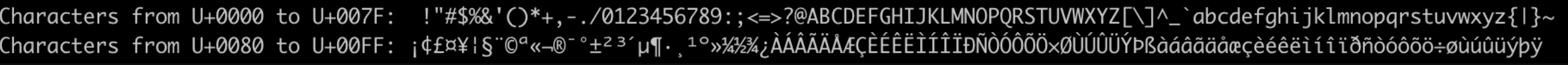
From the output image shown above, it’s evident that you can split the characters based on group and display them based on your required groups. If you are working with specific character sets, you can analyze the specific group and avoid dumping everything in the console, like the first approach we saw in this post.
Method 6: Using the string module
Another module we should discuss is “string”. This modus operandi is helpful when a built-in string module defines printable characters.
Here’s the script that demonstrates it clearly:
import string
printable_chars = ''.join(char for char in map(
chr, range(0x110000)) if char in string.printable)
print(printable_chars)
Output

The above screenshot displays only the characters likely to render well in most contexts, avoiding control characters and other non-printable Unicode points. This is used as an advantage because it removes all the non-printable unicode points. It guarantees compatibility across different systems.
That’s it!