
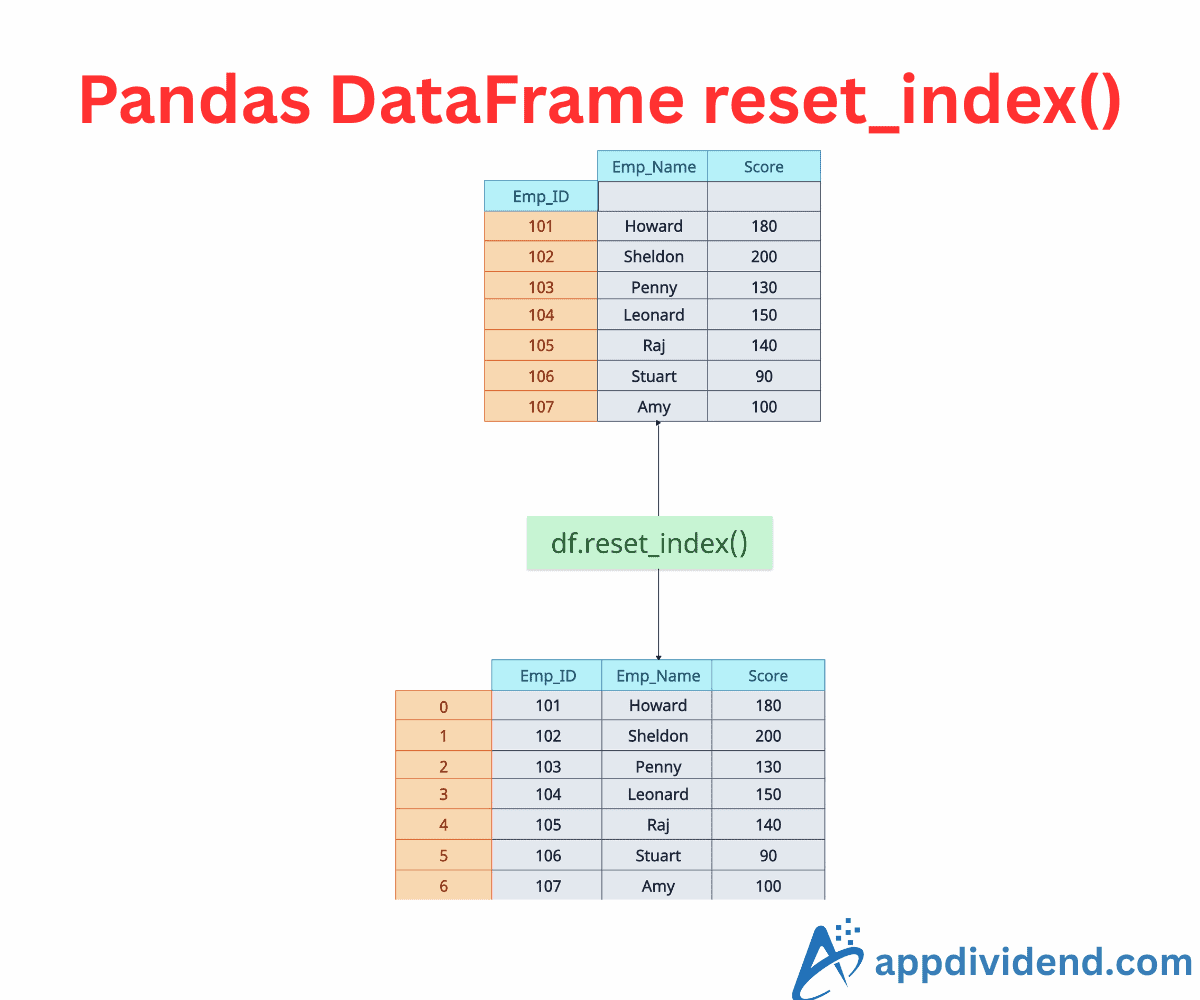
The DataFrame reset_index() method in Pandas resets the index of a DataFrame, replacing it with the default integer index (starting from 0). If the DataFrame has a MultiIndex, it can selectively reset one or more levels.
import pandas as pd
df = pd.DataFrame(
{
'Team_Name': ["Lakers", "Patriots", "Yankees", "Lakers", "Red Sox", "Warriors", "Patriots"],
'Wins': [12, 10, 14, 12, 13, 15, 18]
},
index=[101, 102, 103, 104, 105, 106, 107]
)
print(df)
print(df.reset_index())
In this code, you can see that, first, we had an index of [101, 102, 103, 104, 105, 106, 107] while creating a DataFrame.
Then, we reset the index using the df.reset_index() method. Now, that “index” has become a new column, and the new index will be: [0, 1, 2, 3, 4, 5, 6].
Syntax
DataFrame.reset_index(level=None,
drop=False,
inplace=False,
col_level=0,
col_fill="",
allow_duplicates=lib.no_default,
names=None)
Parameters
| Argument | Description |
| level | It specifies the level(s) to reset in a MultiIndex. |
| drop |
If it is True, it discards the original index instead of inserting it as columns. |
| inplace | If it is True, it changes the DataFrame in place and returns None. |
| col_level | If your DataFrame contains MultiIndex columns, it specifies the level where the reset index labels are inserted. |
| col_fill |
For MultiIndex columns, this argument value fills in other levels when inserting the index. If None, repeats the index name. |
| allow_duplicates | It allows duplicate column labels when inserting the index. |
|
names |
It renames the column(s) created from the reset index. |
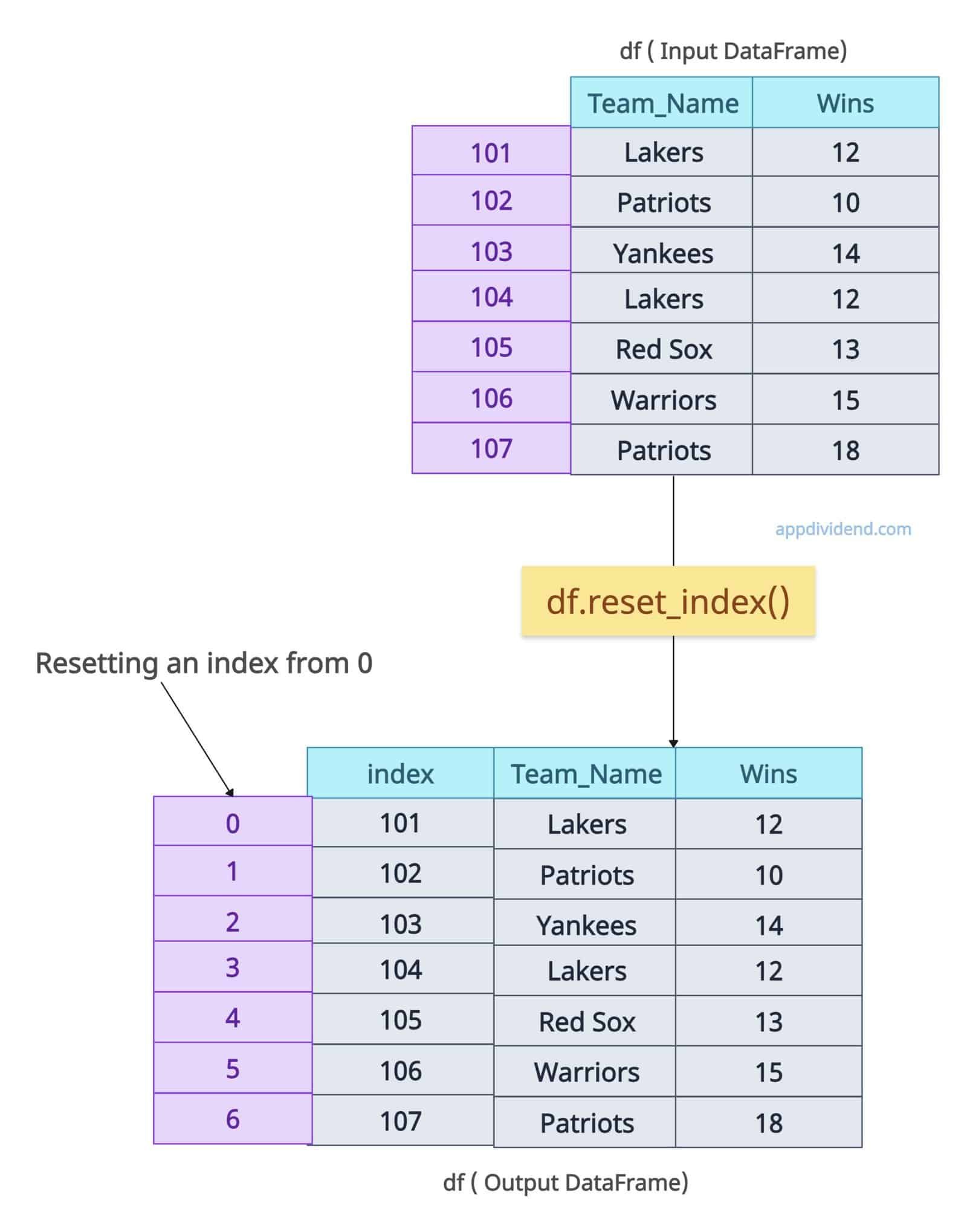
Using drop=True to discard the original Index
The drop=True argument is essential when you are resetting the index. But the question is, why? Well, if you are resetting the index, the old index will become a new column, and the latest index, starting from 0, will be inserted.
So, we can remove the old index column by passing the argument drop=True. It makes it a clean DataFrane with only a single index.
It basically prevents inserting the index as a column.
import pandas as pd
df = pd.DataFrame(
{
'Team_Name': ["Lakers", "Patriots", "Yankees", "Lakers", "Red Sox", "Warriors", "Patriots"],
'Wins': [12, 10, 14, 12, 13, 15, 18]
},
index=[101, 102, 103, 104, 105, 106, 107]
)
print(df)
reset_df = df.reset_index(drop=True)
print(reset_df)
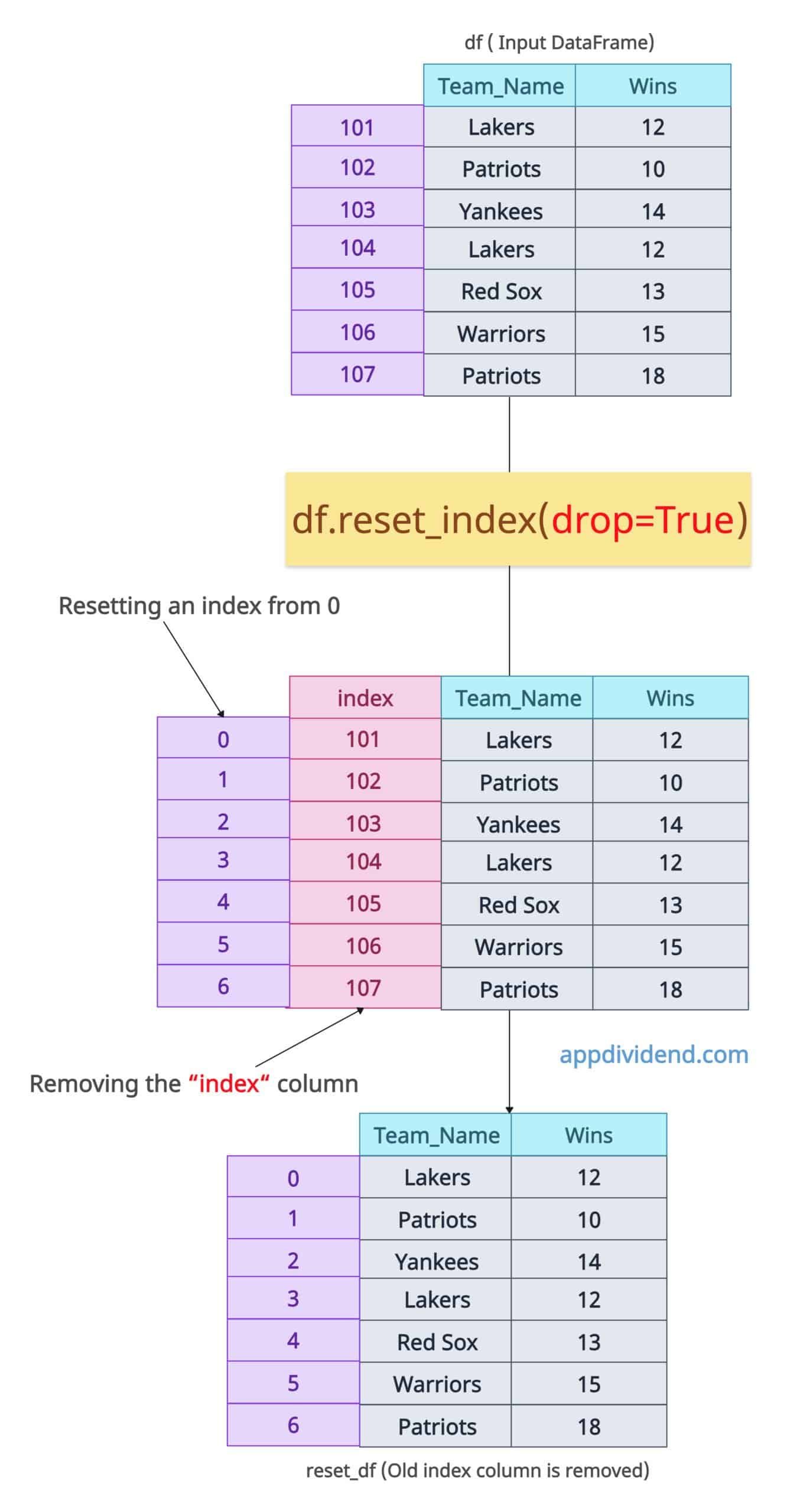
Handling multiIndex
Let’s make “Team_Name” and “Wins” into a MultiIndex using the set_index() method while adding a new column “Loses”.
import pandas as pd
df = pd.DataFrame(
{
'Team_Name': ["Lakers", "Patriots", "Yankees", "Lakers", "Red Sox", "Warriors", "Patriots"],
'Wins': [12, 10, 14, 12, 13, 15, 18],
'Losses': [5, 7, 6, 4, 8, 3, 9]
},
index=[101, 102, 103, 104, 105, 106, 107]
)
print(df)
df_multi = df.set_index(["Team_Name", "Wins"])
print(df_multi)
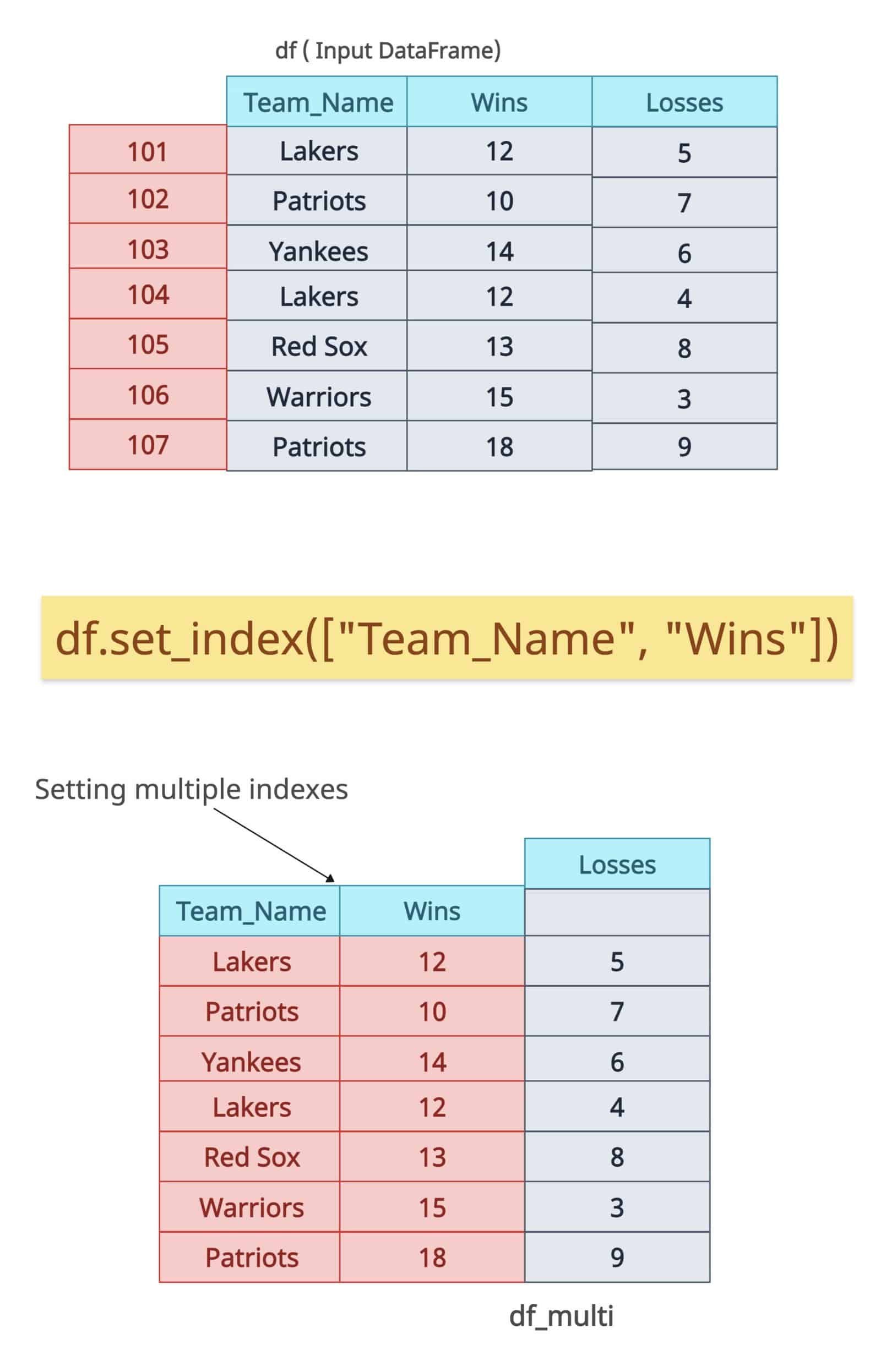
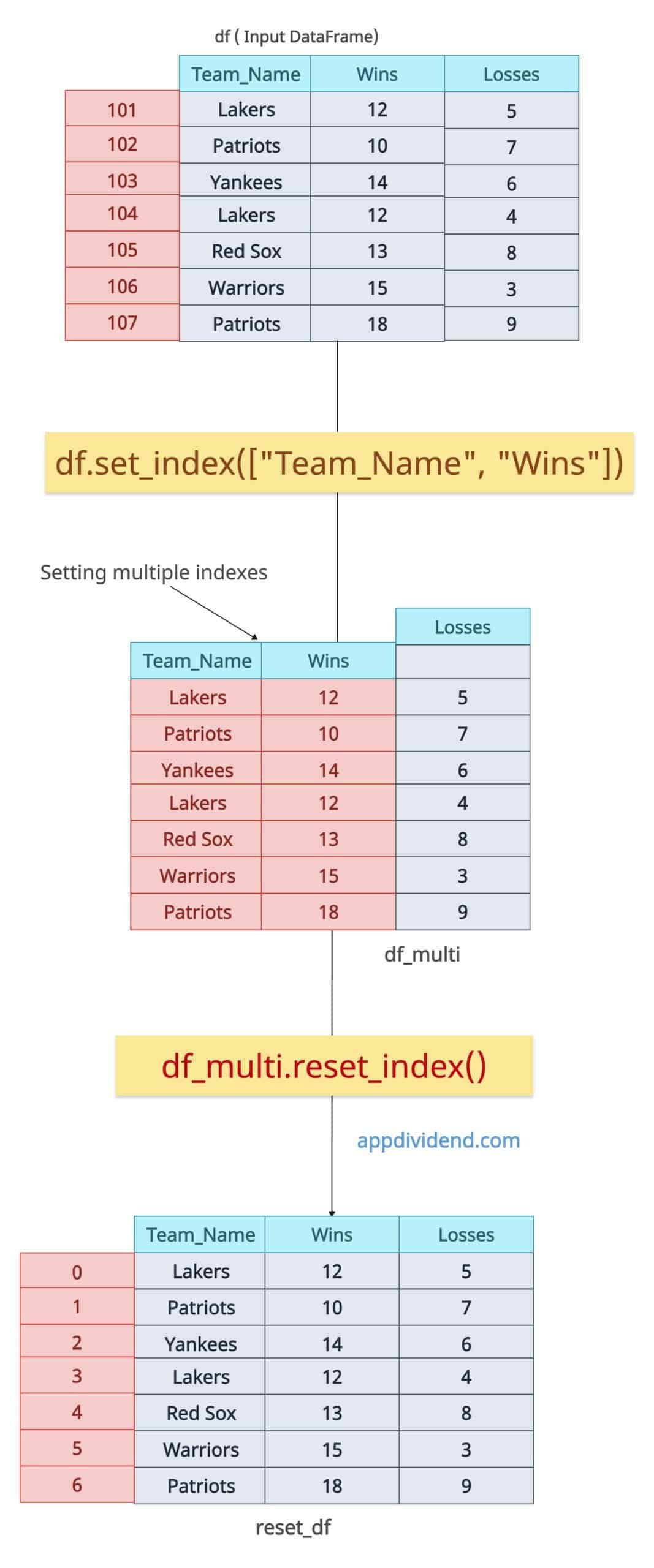
Reset the entire multiIndex
Let’s reset the entire multiindex by using the df.reset_index() method.
So, the new DataFrame will have an index that starts at 0, and the old two indexes will become the columns of the DataFrame.
import pandas as pd
df = pd.DataFrame(
{
'Team_Name': ["Lakers", "Patriots", "Yankees", "Lakers", "Red Sox", "Warriors", "Patriots"],
'Wins': [12, 10, 14, 12, 13, 15, 18],
'Losses': [5, 7, 6, 4, 8, 3, 9]
},
index=[101, 102, 103, 104, 105, 106, 107]
)
print(df)
df_multi = df.set_index(["Team_Name", "Wins"])
print(df_multi)
reset_df = df_multi.reset_index()
print(reset_df)
The above output figure shows that both index levels have returned to their respective columns.
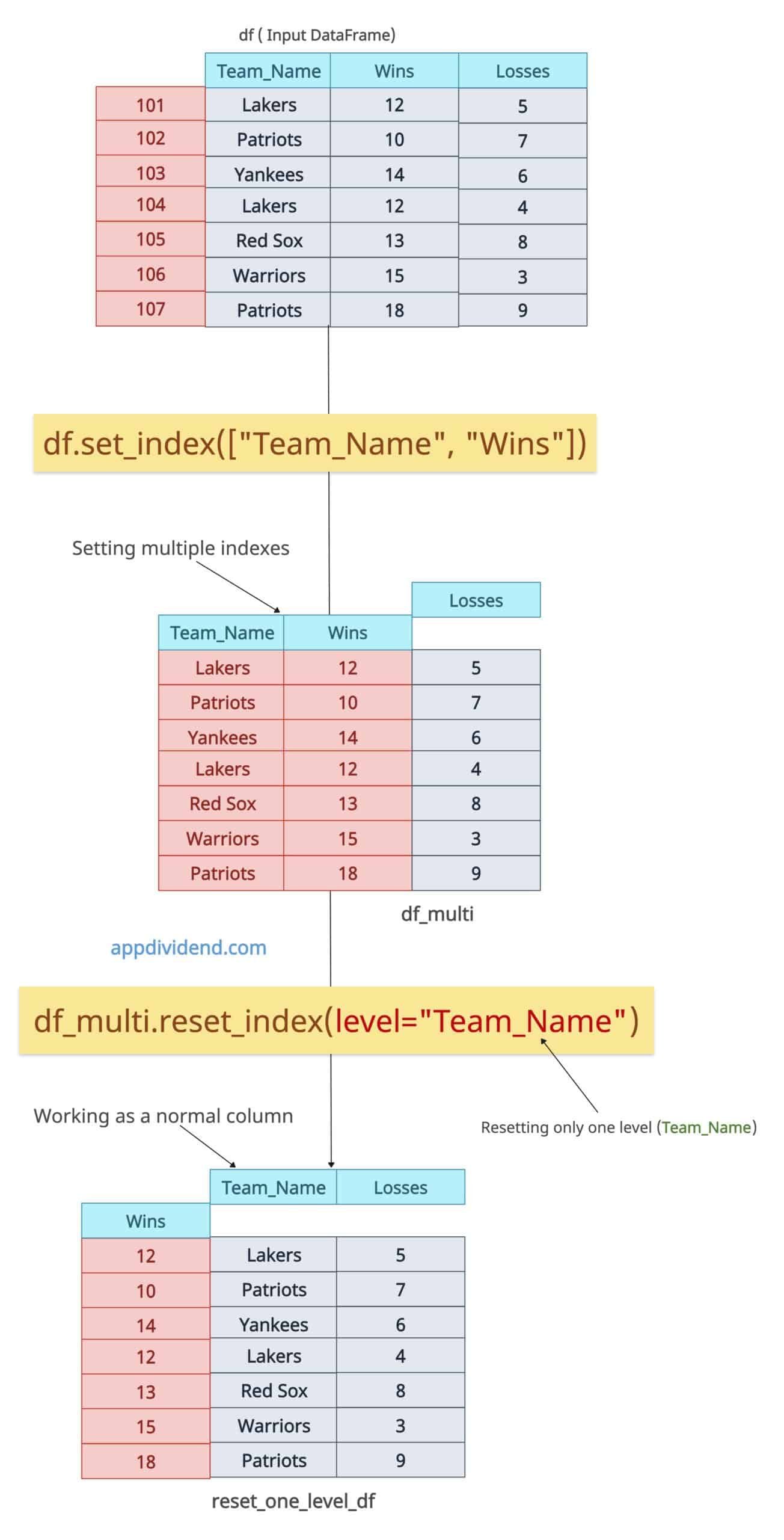
Reset only one level (e.g., Team_Name)
Let’s reset only the “Team_Name” column so that it will become a regular column, and “Wins” will still be an “index”.
import pandas as pd
df = pd.DataFrame(
{
'Team_Name': ["Lakers", "Patriots", "Yankees", "Lakers", "Red Sox", "Warriors", "Patriots"],
'Wins': [12, 10, 14, 12, 13, 15, 18],
'Losses': [5, 7, 6, 4, 8, 3, 9]
},
index=[101, 102, 103, 104, 105, 106, 107]
)
print(df)
df_multi = df.set_index(["Team_Name", "Wins"])
print(df_multi)
reset_one_level_df = df_multi.reset_index(level="Team_Name")
print(reset_one_level_df)
That’s all!