

Here are three ways to extract text from a PDF File in Python:
- Using the “PyMuPDF” library (For simple text or complex formatted text, including tables)
- Using the “tika” library
- Using pdf2image + pytesseract (OCR) (For PDF containing images)
Here are the three different PDFs we will use for this practical example:
- simple.pdf (Contains a simple textual paragraph)
- tabular.pdf (Contains text in the tabular format)
- image_based.pdf (Contains text in the format of images)

In my current project directory, there is a folder called “pdfs,” and inside that folder, I have the three aforementioned PDFs.
Method 1: Using the “PyMuPDF” library
The “PyMuPDF”, also known as “fitz”, is a popular third-party high-performance library used to extract data from PDF files. It can handle text extraction, image extraction, searching, and more.
You can install the library using the command below:
pip install pymupdf
Extracting simple text
Here is the screenshot of the “./pdfs/simple.pdf” file:

If you want to extract the above paragraph from a PDF, you can create a custom function and open a file using the “with fitz.open()” statement and read the content using the “.get_text()” method.
Keep in mind that “pymupdf” can be imported as “fitz” in a Python program:
import fitz # PyMuPDF
def extract_text_pymupdf(pdf_path):
text = ""
with fitz.open(pdf_path) as doc:
for page in doc:
text += page.get_text()
return text
pdf_file = "./pdfs/simple.pdf"
print(extract_text_pymupdf(pdf_file))
Output
Sample PDF with Paragraph This is a sample PDF file that contains a simple text paragraph. It serves as an example of how to generate a PDF document with text using Python. PDFs are widely used for sharing documents in a format that is independent of software, hardware, and operating systems.
We get all the content from that PDF without losing any information.
Extracting text in tabular format
How about the text in the “Tabular Format”. Many important pieces of information are constructed in a tabular format. Here is the screenshot of the “tabular.pdf” file’s content:

How do you read this file and extract its content? Here is the code for that as well.
import fitz # PyMuPDF
def extract_formatted_text(pdf_path):
with fitz.open(pdf_path) as doc:
for page in doc:
blocks = page.get_text("blocks")
for block in blocks:
print(f"Block: {block[4]}")
print(f"Bounding Box: {block[:4]}")
print("---")
pdf_file = "./pdfs/tabular.pdf"
print(extract_formatted_text(pdf_file))
Output

You can see from the above output image that we got each row in the form of a block of the table.
Extracting images from PDF
The standout benefit of the pymupdf library is that it allows you to extract an image from a PDF, whether the PDF contains a single image or multiple images.
You can pluck the images and save them in your current project folder.
Here is the screenshot of the “image_based.pdf” file that contains images:
The above PDF file contains 8 images, and we will extract all of them and save them in the current working directory using the code below:
import fitz # PyMuPDF
# Extract images
def extract_images(pdf_path):
with fitz.open(pdf_path) as doc:
for i, page in enumerate(doc):
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# Save the image
with open(f"image_page{i+1}_{img_index+1}.png", "wb") as image_file:
image_file.write(image_bytes)
extract_images(pdf_file)
print("Extracted all eight images! Check your current project folder")
Output
Extracted all eight images! Check your current project folder
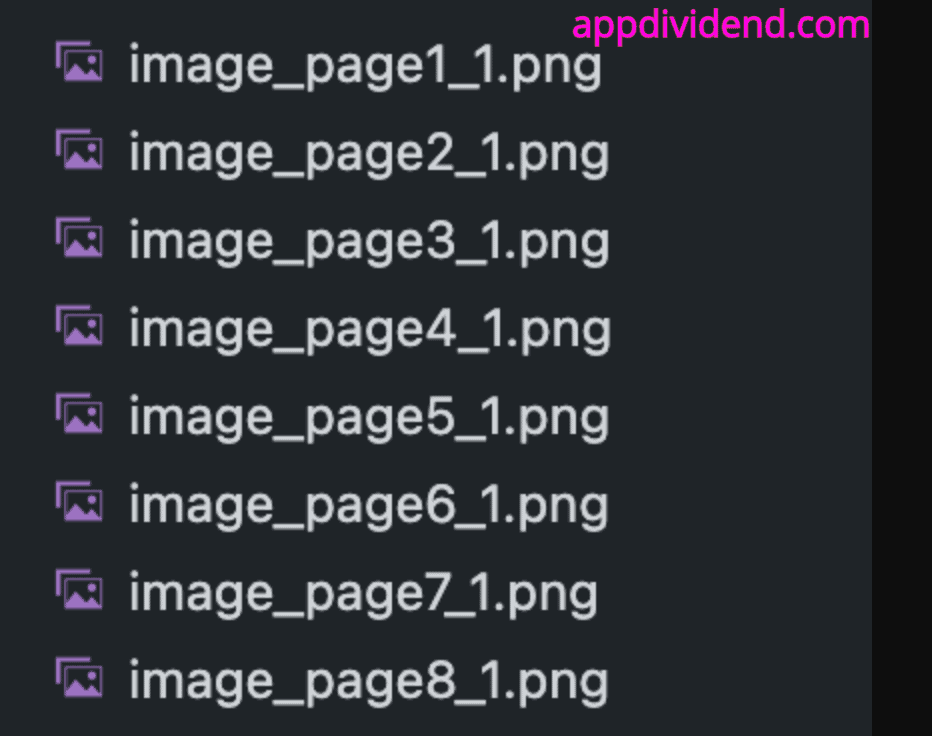
You can see all the images pulled from the PDF.
Method 2: Using the “tika” library
The “Apache tika” is also a well-known library to detect and extract content from not only PDF files but also various other file formats. It provides a “parser.fromfile()” function that returns the raw content of the file.
You can install the “tika” library using the command below:
npm install tika
You can use it in code like this:
from tika import parser
def extract_text_tika(pdf_path):
raw = parser.from_file(pdf_path)
return raw['content']
pdf_file = "./pdfs/tabular.pdf"
print(extract_text_tika(pdf_file))
Output

Method 3: Using pdf2image + pytesseract (OCR)
In real life, you generally not only come across textual or image-type PDFs but also scanned PDFs.
The scanned PDFs are those created by taking a screenshot of written pages and converting them into a PDF, from which you want to extract the text from the scanned images.
For these operations, we need to use the pdf2image and pytesseract libraries. Also, in your system, you must have installed Poppler and Tesseract.
Since I am using macOS, I can use Homebrew to install both of these packages using the command below:
brew install poppler brew install tesseract
If you are using Windows or Linux OS, I would highly recommend that you do a quick Google search and install the packages mentioned above, as per your system.
After that, we can install the following Python-related third-party libraries using the command below:
pip install pdf2image pytesseract
For this approach, I will be using “image_based.pdf” because it is specifically designed to extract the content of the image within the PDF.
from pdf2image import convert_from_path
import pytesseract
def extract_text_ocr(pdf_path):
images = convert_from_path(pdf_path)
text = ""
for image in images:
text += pytesseract.image_to_string(image)
return text
pdf_file = "./pdfs/image_based.pdf"
print(extract_text_ocr(pdf_file))
Output

That’s all!