

Here are three ways to convert DOCX to PDF in Python:
- Using docx2pdf
- Using unoconv with LibreOffice/OpenOffice
- Using python-docx and reportlab
The .pdf and .doc or .docx are the most popular file types for managing files in an application. You can convert Word documents (.doc or .docx) to PDF format using several methods, each with advantages and trade-offs.
For this practical, I will be using a sample.docx file that looks like this:

Method 1: Using docx2pdf
The most popular package to convert a doc file (.doc or .docx) to a PDF file is to use the “docx2pdf” package. It is also platform-independent, meaning it works on Windows.
It leverages Microsoft Word via the COM interface for conversion, ensuring high fidelity. On macOS, it uses JXA (JavaScript for Automation), and on Linux, it falls back to LibreOffice.
You can install the package using pip:
pip install docx2pdf
Here is the complete code:
from docx2pdf import convert
# Convert a single file
convert("./sample.docx", "./document.pdf")
print("Conversion from DOCX to PDF completed successfully!")
Output

Method 2: Using unoconv with LibreOffice/OpenOffice
The unoconv is LibreOffice’s uno binding for conversions. It supports a wide range of formats and preserves formatting well.
To use this approach, you need to install LibreOffice. Since I am using MacOS, I can install it using the command below:
# Install LibreOffice brew install --cask libreoffice # Install unoconv brew install unoconv
Ensure you have installed Homebrew.
Here is the complete code:
import subprocess
def convert_with_unoconv(input_file, output_file):
subprocess.call(['unoconv', '-f', 'pdf', '-o', output_file, input_file])
# Usage
convert_with_unoconv('./sample.docx', './document.pdf')
print("DOC file is converted into PDF")
Output

If everything is installed and configured correctly, it should convert the Docx to a PDF file.
Method 3: Using python-docx and reportlab
The combination of python-docx and reportlab libraries can do the job by first reading and manipulating DOCX files using “python-docx” and the “reportlab” library to generate PDFs from that file.
Here is the step-by-step implementation:
- Read the .docx file using the python-docx library.
- Extract the text and images from the docx file.
- Generate a PDF using reportlab by adding the extracted content.
Install both libraries using the command below:
pip install python-docx reportlab
Here is the complete Python code:
from docx import Document
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def convert_with_python_docx(input_file, output_file):
# Read the .docx file
doc = Document(input_file)
full_text = []
for para in doc.paragraphs:
full_text.append(para.text)
# Generate PDF
pdf = canvas.Canvas(output_file, pagesize=letter)
textobject = pdf.beginText(40, 750)
for line in full_text:
textobject.textLine(line)
if textobject.getY() < 50:
pdf.drawText(textobject)
pdf.showPage()
textobject = pdf.beginText(40, 750)
pdf.drawText(textobject)
pdf.save()
# Usage
convert_with_python_docx('./sample.docx', './document.pdf')
Output
Conversion time for comparison of different approaches
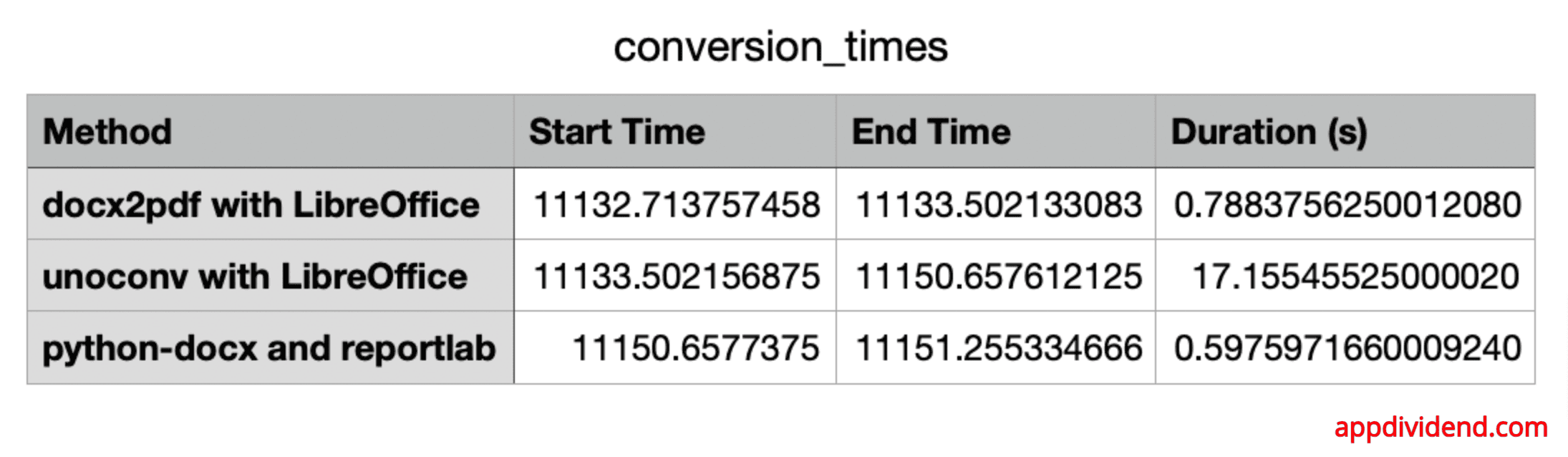
We used the “time” module to check the processing time for each method, and I created a table based on my observation:
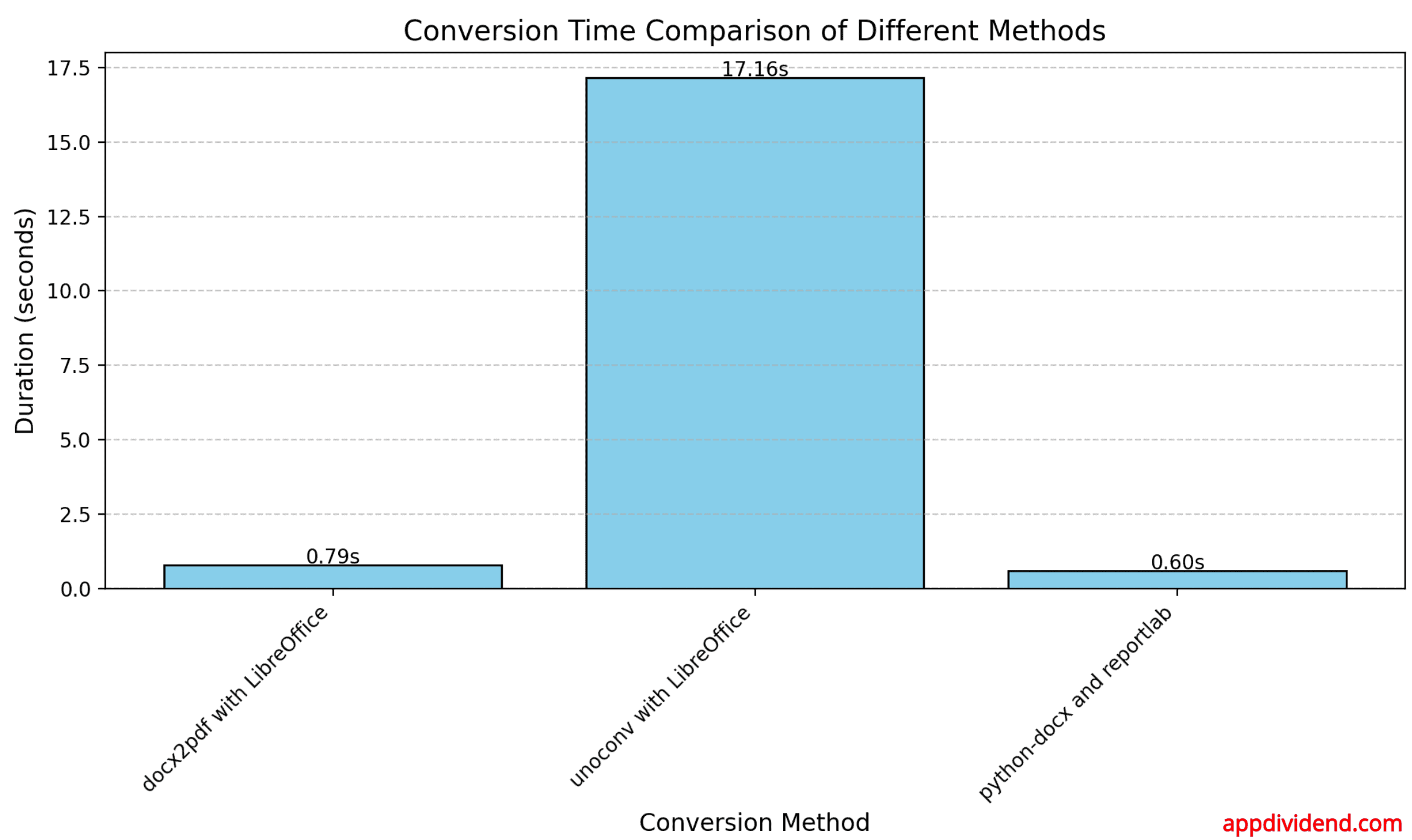
- The fastest method is “python-docx and reportlab”
- The second fastest is “docx2pdf with LibreOffice”
- The slowest method is “unoconv with LibreOffice”
Here is the chart based on the above observation:
That’s it!