
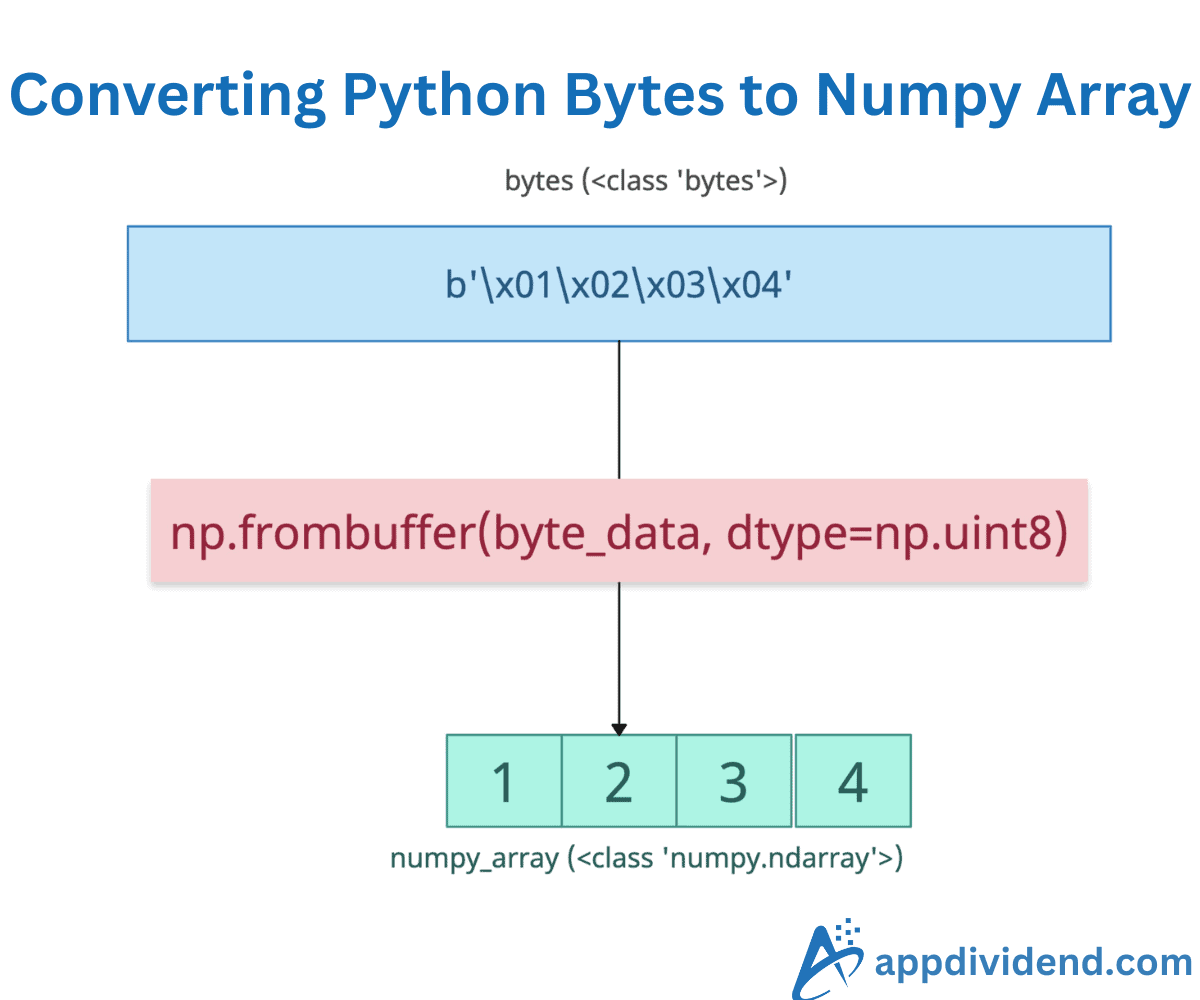
The fastest and most correct way to convert a Python bytes object to a numpy array is to use the np.frombuffer() method. It is a zero-copy method and interprets a buffer as a 1D array.
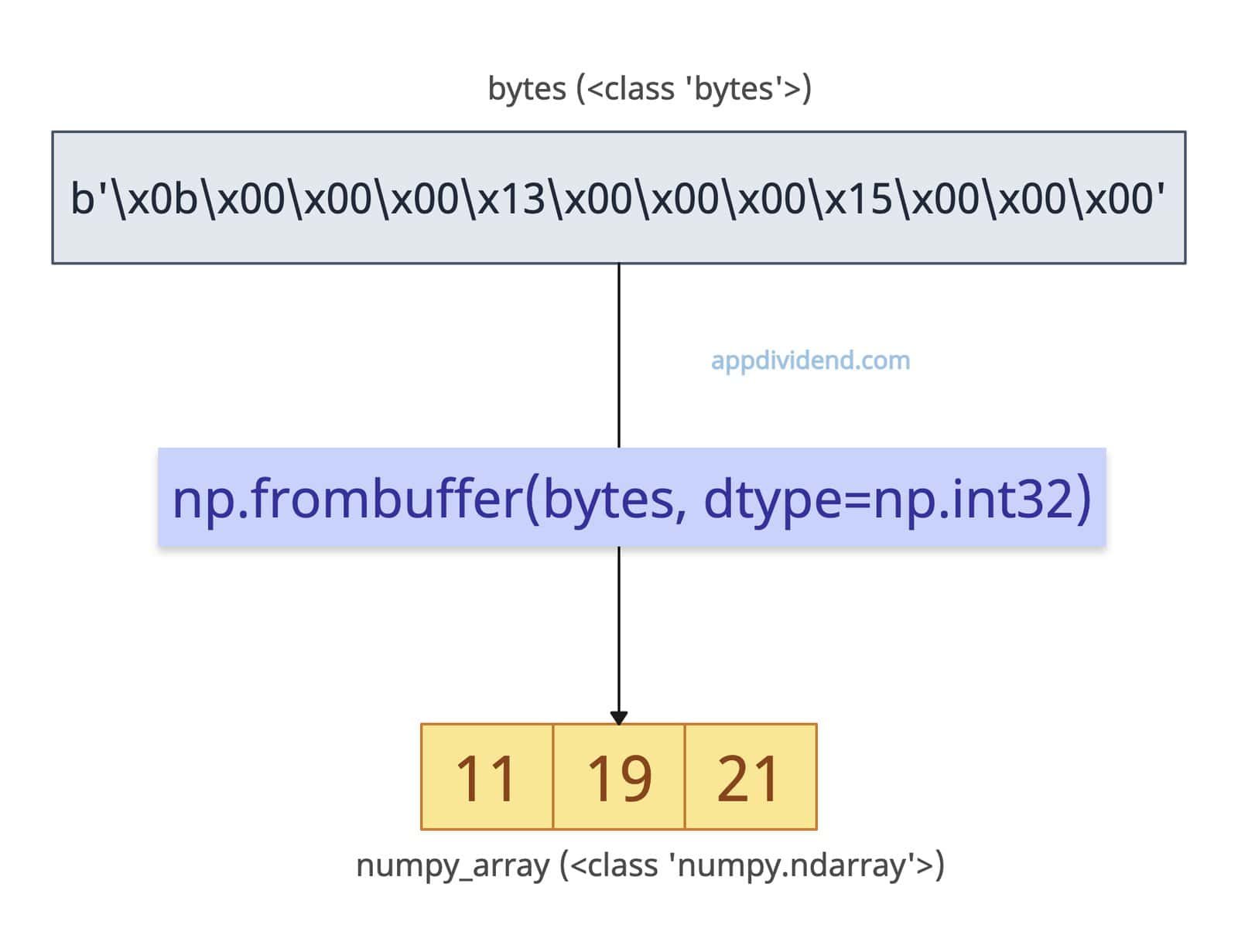
import numpy as np bytes = b'\x0b\x00\x00\x00\x13\x00\x00\x00\x15\x00\x00\x00' print(bytes) # Output: b'\x0b\x00\x00\x00\x13\x00\x00\x00\x15\x00\x00\x00' print(type(bytes)) # Output: <class 'bytes'> numpy_array = np.frombuffer(bytes, dtype=np.int32) print(numpy_array) # Output: [11 19 21] print(type(numpy_array)) # Output: <class 'numpy.ndarray'>
In this code, we have defined bytes and want to convert them to a numpy array of integers. So, we passed it to the np.frombuffer() method and it returns a proper numpy array.
We verified the data types before and after conversion using the type() method.
Floating-point conversion
Let’s say we have a bytes object and we want to convert a numpy array of float values.
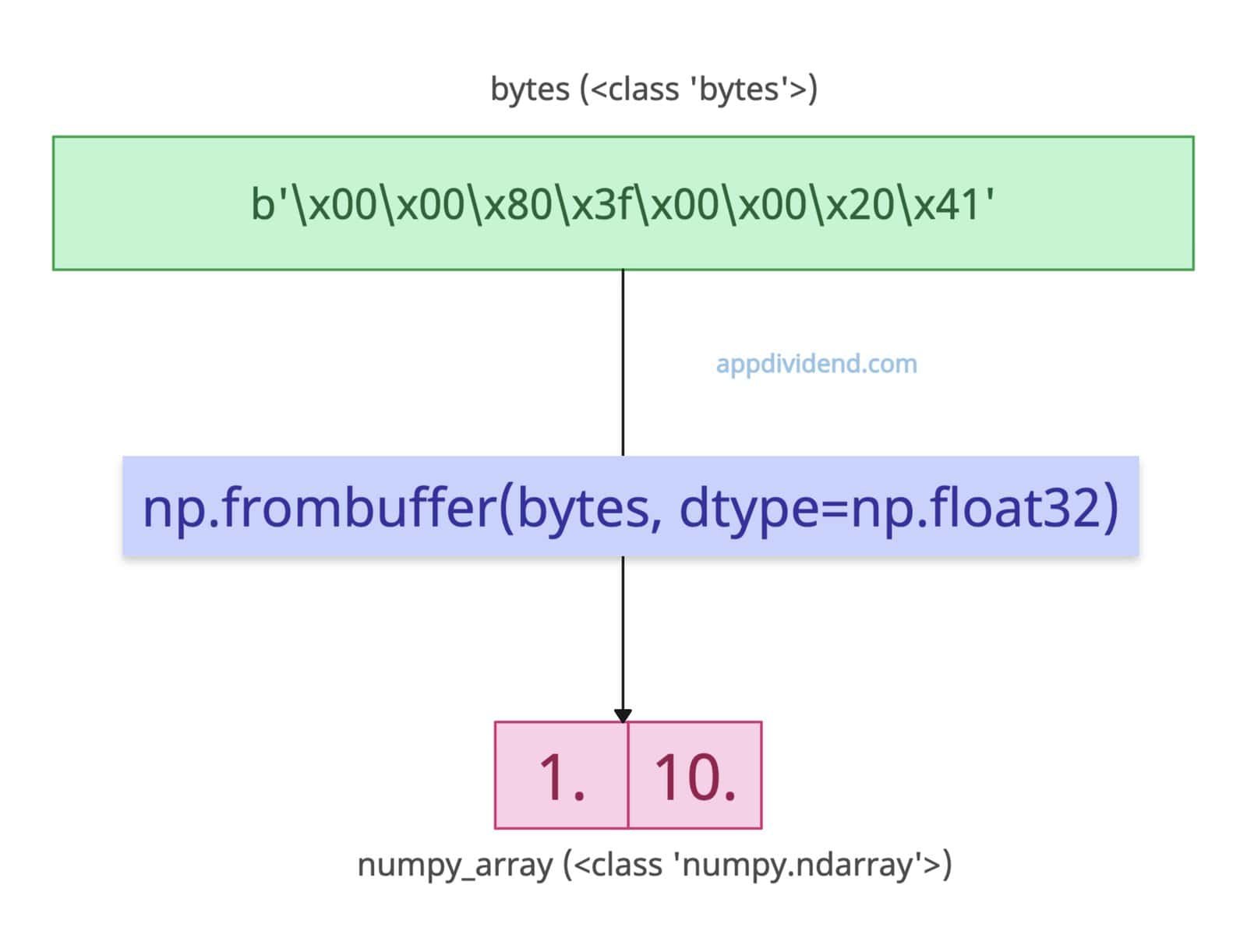
import numpy as np bytes = b'\x00\x00\x80\x3f\x00\x00\x20\x41' print(bytes) # Output: b'\x00\x00\x80\x3f\x00\x00\x20\x41' print(type(bytes)) # Output: <class 'bytes'> numpy_array = np.frombuffer(bytes, dtype=np.float32) print(numpy_array) # Output: [ 1. 10.] print(type(numpy_array)) # Output: <class 'numpy.ndarray'>
It specifies float32 for 4-byte floats.
Image/Pixel Data (e.g., Grayscale Bytes to 2D Array)
Let’s say we have an input of uint8 pixels as bytes, and we want an output of a 2D numpy array. For that, we need to reshape the final array into a two-dimensional array using the .reshape() method.
![]()
import numpy as np image_bytes = b'\x00\xFF\x00\xFF\xFF\x00\xFF\x00\x00\xFF\x00\xFF\xFF\x00\xFF\x00' print(image_bytes) # Output: b'\x00\xFF\x00\xFF\xFF\x00\xFF\x00\x00\xFF\x00\xFF\xFF\x00\xFF\x00' print(type(image_bytes)) # Output: <class 'bytes'> array_2d = np.frombuffer(image_bytes, dtype=np.uint8).reshape(4, 4) print(array_2d) # Output: # [[ 0 255 0 255] # [255 0 255 0] # [ 0 255 0 255] # [255 0 255 0]] print(type(array_2d)) # Output: <class 'numpy.ndarray'>
Rare conversion: np.fromiter() (For Iterable Bytes, Rare)
If your bytes are not raw numeric bytes (e.g., UTF-8 “123”, not 0x7B). The np.frombuffer() method will misinterpret it; in this case, use np.fromiter().
import numpy as np bytes_obj = b'\x01\x02\x03' print(bytes_obj) # Output: b'\x01\x02\x03' print(type(bytes_obj)) # Output: <class 'bytes'> arr_1d = np.fromiter(bytes_obj, dtype=np.uint8, count=len(bytes_obj)) print(arr_1d) # Output: [1 2 3] print(type(arr_1d)) # Output: <class 'numpy.ndarray'>
It treats bytes as iterable, and that is why it is slower; use only if bytes are lazily generated.
That’s all!